
Lab Mission
We study how people read by using eye tracking experiments, electrophysiology (i.e., “brain wave”) experiments, advanced statistical techniques, and cognitive models. We explore how visual perception is shaped by language knowledge and context.


How is visual perception shaped by language knowledge and context?
Word Recognition Across the Visual Field
As we read, the words outside our center of vision are fuzzy (i.e., low-acuity), but when we directly fixate on words in the center of vision, we can view them with high-acuity. Our lab investigates how much information readers get before they look directly at words, and what aspects of words readers pre-activate during reading (i.e., orthography, meaning, etc.). When readers recognize letters within words faster than within non-words or in isolation, this is referred to as the word superiority effect.
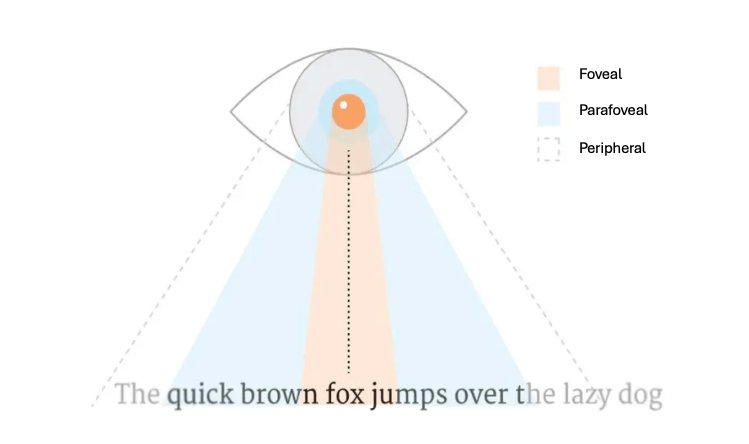
Words in Context | Individual Differences
With eye-tracking, we can investigate the relationship between expectations generated by sentence context, visual word form properties, and word frequency (i.e., how common the word is). Our research also focuses on how semantic properties (e.g., predictions about upcoming word meanings; semantic diversity of preceding words) interact with visual information from upcoming words to achieve word recognition. However, sentence context may mean different things to different people, therefore we also explore how reading behavior differs across individual groups of people.
How does a reader’s motivation and goals guide their behavior and comprehension?
While reading, an individual’s primary goal is to attempt to understand what words and sentences mean. However, sometimes they may have a different goal. These differing demands may require readers to focus on specific components in order to successfully complete the task. Our lab focuses on investigating specific eye-movement behaviors and/or brain responses that may differ depending on these specific goals. Some examples of ongoing projects including proofreading or coordinating their eye and voice to read aloud.
How is reading behavior coordinated with neural processes and language comprehension?
Successfully reading involves decoding language meaning, but also making decisions about where to move your eyes and which word to look at in a given moment. Sometimes readers read rather quickly and even skip over words without looking at them. In other cases, when the text is confusing, for example, a reader may move their eyes backward to an earlier point to look at previous words again. Reading researchers are still trying to understand the relationship between word recognition, language comprehension, and how and why people make the eye movement decisions that they do. To better understand this complex cognitive process, we record brain activity using EEG and eye movements using an eye-tracking camera and align these data in time. Using this method, we can then isolate brain responses that are specific to particular types of eye movements and particular aspects of the language. Using this method, we aim to better understand language comprehension and eye movement planning in the brain in real time during the reading process.
What is unique about skilled deaf readers?
Skilled deaf readers are a unique group that is highly efficient at reading. They read faster (i.e., more words per minute) and skip words more often than hearing readers, without diminishing their overall reading comprehension. We find that this increased efficiency is related to deaf readers’ ability to take in information from a wider area of their visual periphery – both to the left and right of fixation. Additionally, deaf readers’ wider spans are related to both their increased reading speed and comprehension ability, suggesting that they do not experience a speed-accuracy trade-off in reading in the same way as hearing readers. Our research aims to further investigate what is distinctive about skilled deaf readers, and what types of linguistic processes (e.g., lexical and/or contextual) they engage in across the visual field (i.e., at fixation and to the left and right) to engage in efficient reading.
OUR METHODOLOGY
This video describes our methodology but reflects research projects from 2022. For our current research, please see descriptions above.
We would like to thank ORod Visual Productions for their amazing work on this video. Please visit https://ovizpro.com to learn more
